Dear listers
I would really like to make a heat map of some events over time.
But i cannot seem to wrap my head around how to do it.
an example data could look like this:
when i write
the example data looks fine, but i have 17 event codes and 20 age_gr, and frankly it turns out a bit messy.
I thought of heat mapping using hmap, but the data format in the example in the help files are different from mine.
what i would like is something that looks like this:
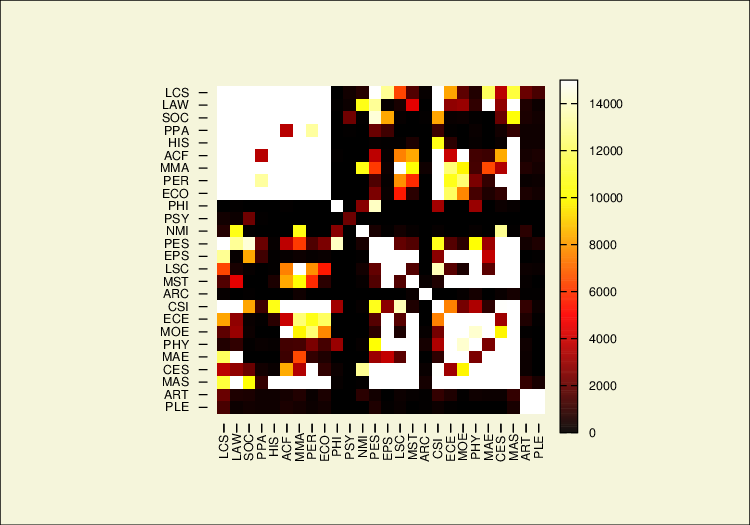
but with the scale going from 0 to 100% (keeping in mind that the data in my set is % with 4 decimal points) and the x-axis being the age_groups
Is this doable?
Thank you.
Lars
I would really like to make a heat map of some events over time.
But i cannot seem to wrap my head around how to do it.
an example data could look like this:
Code:
input group age_gr event1 event2 event3 event4 event5 1 1 10 20 30 20 20 0 1 5 5 5 5 80 1 2 40 10 30 5 15 0 2 25 25 25 25 0 1 3 25 15 30 20 10 0 3 10 20 30 30 10 end
Code:
preserve keep if group==1 graph bar event*, over(age_gr) stack restore
I thought of heat mapping using hmap, but the data format in the example in the help files are different from mine.
what i would like is something that looks like this:
but with the scale going from 0 to 100% (keeping in mind that the data in my set is % with 4 decimal points) and the x-axis being the age_groups
Is this doable?
Thank you.
Lars
Comment