I am working on the Environmental Kuznets Curve, so I want to get graphs for all the countries within each region, like in the following code:
However, I would like to add a xline for each country within the graph. I want this line to account for the year in which each country reached its industrialization peak. Since each country reached this point at a different year, I cannot establish a single xline. I have two variables for this: year_industrialized, which is simply the industrialization peak year, and year_dummy which equals 1 if year >= year_industrialized.
I tried to run this:
But I get this error:
How can I get these xlines for each country?
For clarification, the picture below is what I aim to obtain: a line which represents the "turning point"
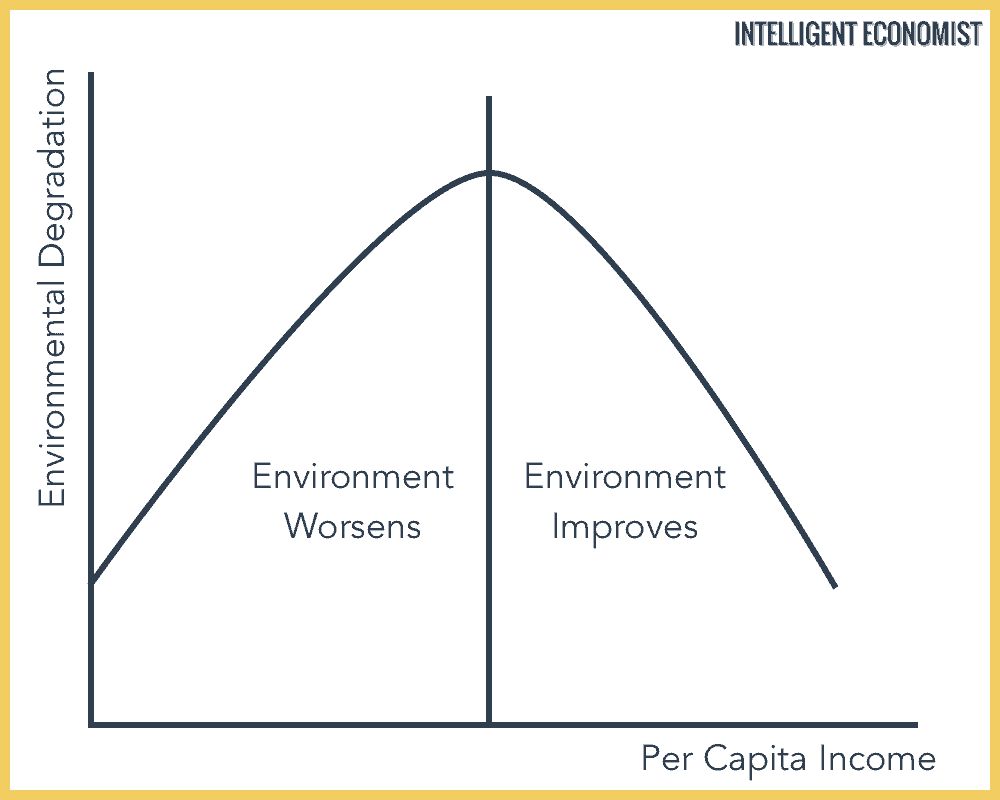
This is a preview of my dataset:
graph twoway scatter co2 gdppc if latin_america==1, by(countryname) ytitle("CO2 emissions") xtitle("GDP per capita")
I tried to run this:
graph twoway scatter co2 gdppc if latin_america==1, by(countryname) ytitle("CO2 emissions") xtitle("GDP per capita") xline(year_industrialized)
xline(year_industrialized) is not a twoway plot type
For clarification, the picture below is what I aim to obtain: a line which represents the "turning point"
This is a preview of my dataset:
Code:
* Example generated by -dataex-. To install: ssc install dataex clear input str18 countryname float co2 double gdppc int year str27 regionname float(latin_america year_industrialized year_dummy) "Argentina" 42100 8861 1960 "Latin America and Caribbean" 1 1976 0 "Argentina" 44100 9344 1961 "Latin America and Caribbean" 1 1976 0 "Argentina" 46300 9049 1962 "Latin America and Caribbean" 1 1976 0 "Argentina" 43300 8695 1963 "Latin America and Caribbean" 1 1976 0 "Argentina" 48100 9446 1964 "Latin America and Caribbean" 1 1976 0 end
Comment