Dear Statalists,
I have one fundamental question that may need your kind help. Think it is a simple loop programming. I need to calculate stock returns for each firm (panel data), identified through a FirmID, as 1 year buy-and-hold stock returns through the annual/yearly share prices. A short version and generalized version of my data information has been shown as below:
Could you please show me how to deal with the loop coding?
Many thanks in advance.
Best!
I have one fundamental question that may need your kind help. Think it is a simple loop programming. I need to calculate stock returns for each firm (panel data), identified through a FirmID, as 1 year buy-and-hold stock returns through the annual/yearly share prices. A short version and generalized version of my data information has been shown as below:
Could you please show me how to deal with the loop coding?
Many thanks in advance.
Best!
Attached Files


 denotes price on year
denotes price on year 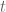 .
.
Comment